
instead of learning from
Honza @Novoj Novotný
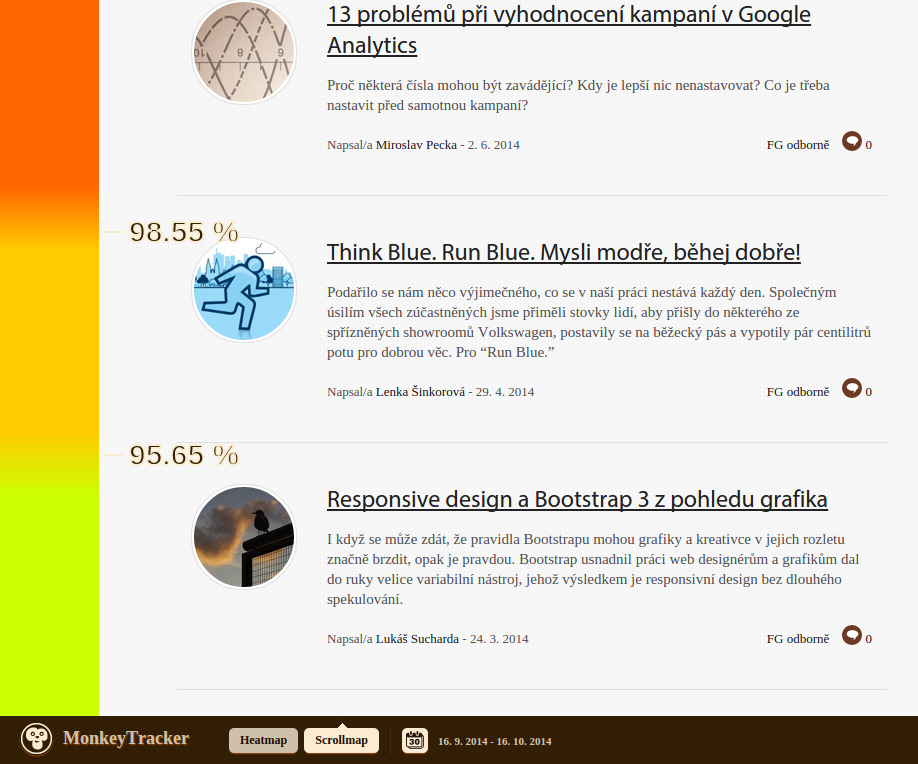
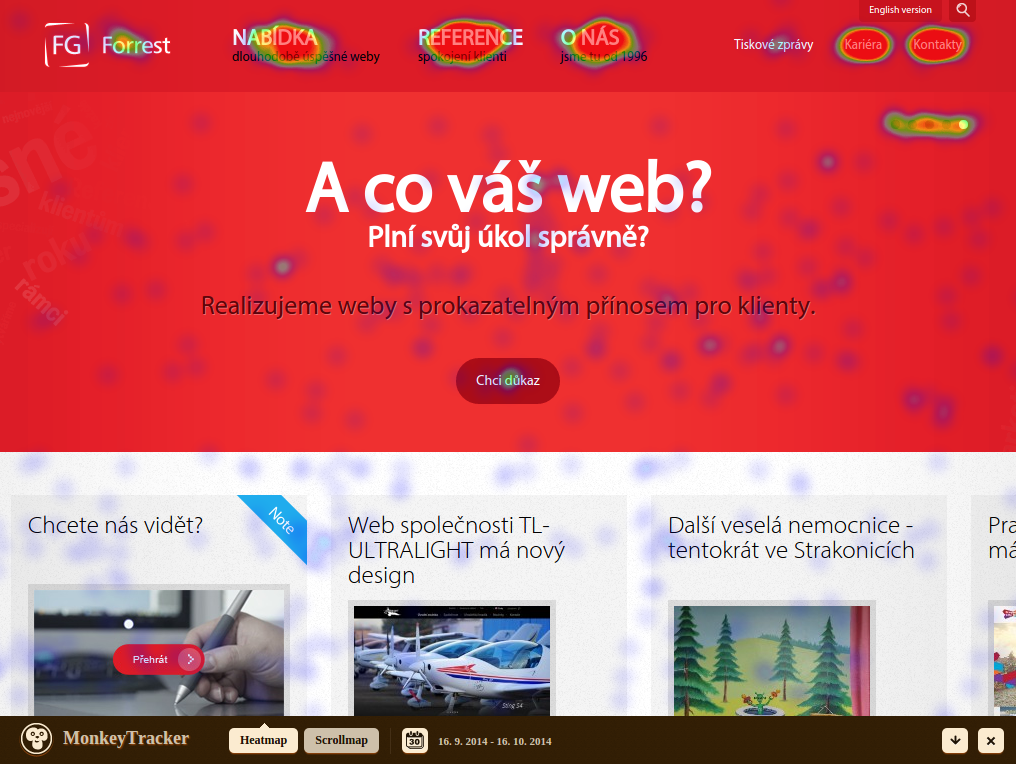
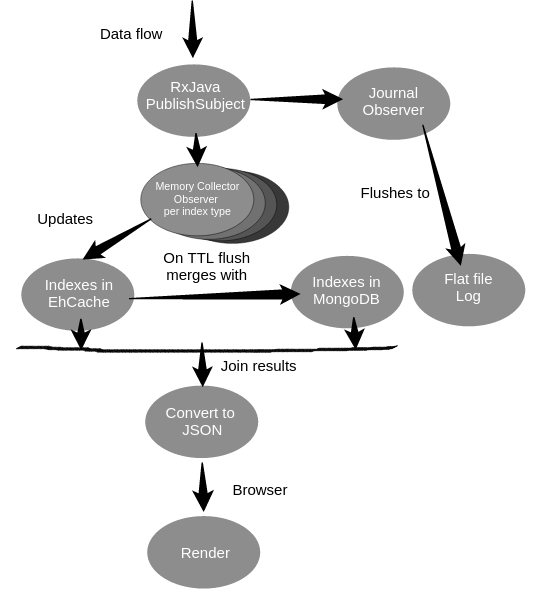
Generating click / scroll heatmaps
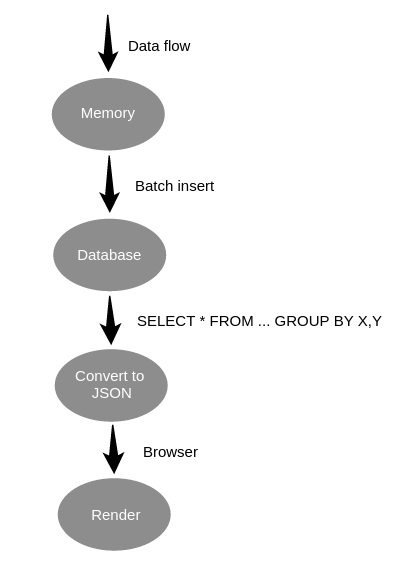
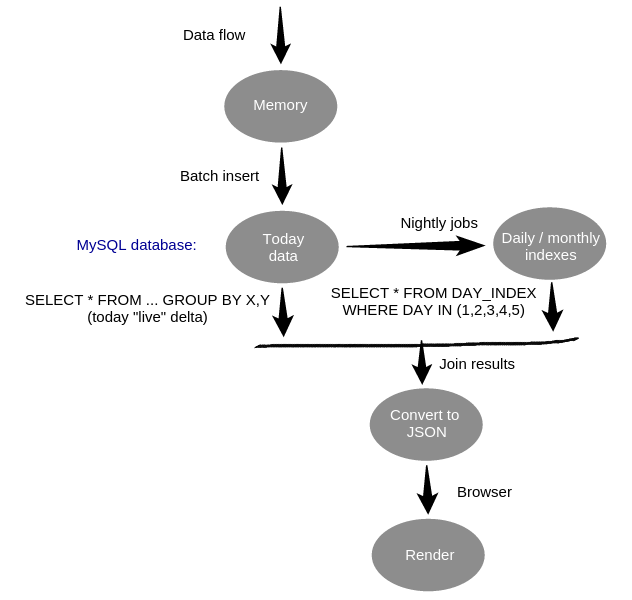

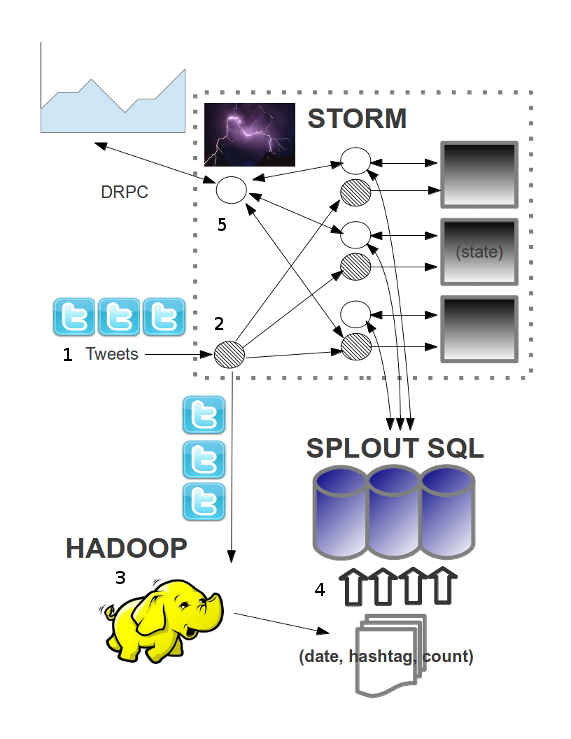
count hashtag appearances in tweets by day / hour
lambda-architecture.net
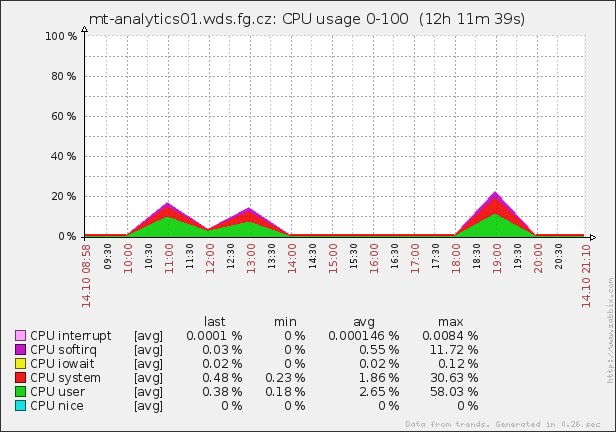
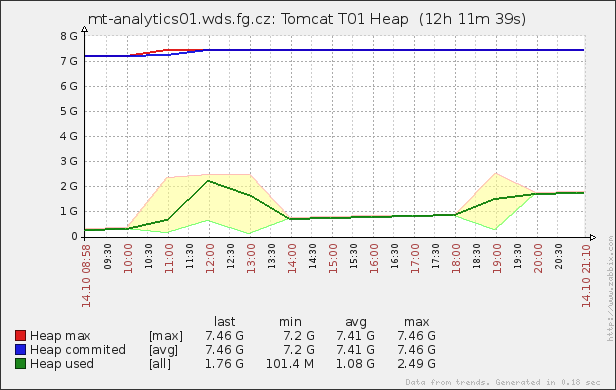
no BIG data yet, no SMALL data already
{
"db" : "monkeyTracker",
"objects" : 3908201,
"avgObjSize" : 395.4592550383156,
"dataSize" : 1545534256,
"storageSize" : 1913036800,
"indexSize" : 756549808,
"fileSize" : 4226809856,
}
| Month | Clicks | Scrolls |
|---|---|---|
| November | 4,641,660 | 2,668,661 |
| December | 8,016,352 | 3,940,576 |
| January | 8,088,716 | 4,557,283 |
| February | 9,759,176 | 5,012,504 |
| Total | 33,931,572 | 17,402,555 |
Questioning the Lambda Architecture (LinkedIn)
www.Kappa-Architecture.com
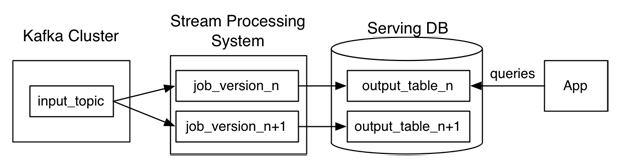
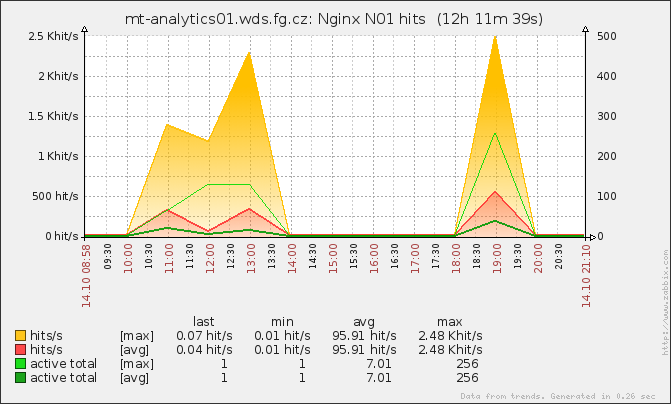
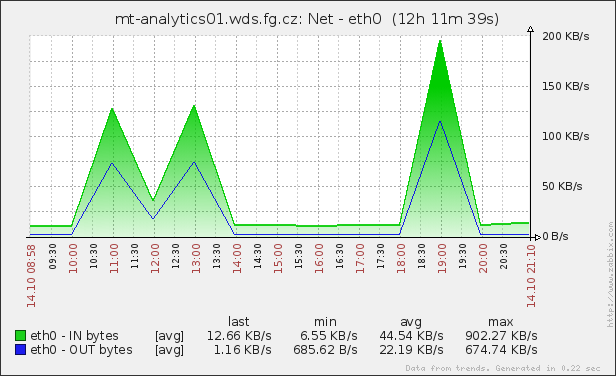
Not without problems ...

Honza Novotný, FG Forrest
@novoj
http://blog.novoj.net